I've recently been working on a project where we push data from an on-premise database to a set of Azure SQL databases daily, and use that Azure SQL database as the source for a Power BI dataset. The dataset gets refreshed once a day.
Our Azure SQL data marts are pretty small - all but one of them are under 2 GB, and the largest one is about 3 GB. The ETL and Power BI refresh happen overnight - the ETL starts at 1 am, and the Power BI refresh is scheduled at 3 am.
In my SSIS packages, I am loading a few tables that have anywhere from a few thousand to hundreds of thousands of rows in them, and a few tables that have less than 100 rows.
For the small tables, I just truncate them and insert the new rows.
For the large tables, I use some change detection logic to determine which rows are the same in Azure as in the source, and which ones are new or changed, and which ones should no longer exist in Azure. That pattern will be the subject of another blog post.
What I was finding was that I was exceeding my DTU allocation for my Azure SQL databases frequently, and Azure was restricting the SQL database's response times according to its DTU limit.
I decided that I could decrease the overnight data refresh window by scaling up the Azure SQL databases before loading them, and scaling them down again after the Power BI refresh was complete.
After a failed attempt at using Azure automation and adapting a runbook that uses AzureRM PowerShell scripts to set database properties, I happened across this T-SQL equivalent.
ALTER DATABASE MyAzureDb MODIFY (Edition='basic', Service_objective='basic')
When you run this statement, it returns immediately. In the background, Azure is making a copy of the current database with the new service objective level, and when the new copy is ready, it swaps out the current database for the new copy. Based on how much activity is happening at the time of the switch, the change will be transparent to any existing connections. Microsoft does warn that some transactions may be rolled back, so I wanted to wait until the scaling request was complete before I started the heavy-duty ETL (even though I did build in retry logic into my SSIS packages).
Finding the T-SQL that told me when a scale request was complete was a little more difficult. If you try this:
select DATABASEPROPERTYEX('MyAzureDb','Edition') as Edition, DATABASEPROPERTYEX('MyAzureDb','Service_Objective') as ServiceObjective
... you will see the old service objective until the switch occurs. However, if you happen to try another ALTER Database statement to change the objective again while the switch is still happening, you'll get an error message like this:
A service objective assignment on server 'yyyyy' and database 'CopyOfXXXX' is already in progress. Please wait until the service objective assignment state for the database is marked as 'Completed'.
So I went looking to find this "objective assignment state" which was a little difficult to find. Eventually, I came across the Azure SQL-only view sys.dm_operation_status that tells me all the operations that are applied in Azure SQL. It has a row for every operation, so if you've done a few service objective changes, you'll see a row for each. So basically I needed to find the most recent operation and see if it has an IN_PROGRESS status.
with currentDb as (
select *,
row_number() over (partition by resource_type, major_resource_id, minor_resource_id order by start_time desc) as rowNum
from sys.dm_operation_status)
select
major_resource_id as DbName,
operation,
state,
state_desc,
percent_complete,
error_code,
error_desc,
error_severity,
start_time
from
currentdb
where
rowNum = 1
and resource_type_desc = 'Database'
You must be in master to get any results back from sys.dm_operation_status. This is what it returns for me:

You can see that I kicked off some service objective changes that were in progress when I captured this image.
In my scenario, I had several databases that I wanted to scale, and I had metadata in my on-premise database that specified what the scale up level was (S2) and the base level (most of them were basic, but one was larger than 2GB so it had to be S0). I wrote a stored procedure that returned a script containing all the ALTER DATABASE statements, and a WHILE loop that slept for 10 seconds if there were any rows in the sys.dm_operation_status view that were IN_PROGRESS.
In an SSIS package, I called the stored procedure in the on-premise database to get the script, and then I executed the script in the Azure SQL Server (in the master database context). The script would run as long as the service objective changes were still in progress in any database. In my case, this was only a couple minutes. (It takes much less time to change service objectives if you stay within the same edition - Standard or Premium. Moving between Basic and Standard or vice versa probably involves more changes in Azure.)
If I needed to, I might have separated the ALTER DATABASE script from the WHILE IN_PROGRESS script, and then only had the wait script for a specific database, not all databases that I changed. I just kept it simple.
And to help you out, I'm going to simplify it even further - here is a script to create a stored proc that takes the database name and service objective as input parameters, and returns a script that you execute on your SQL Azure server. The stored procedure can be created in an Azure SQL database if you like, or somewhere on your own server. Or you can just take this code and adapt it for your own use. The output script will change the service objective level for one database and wait until it is complete.
create proc Control.AzureDbScale (@dbName sysname, @serviceObjective nvarchar(20))
as
-- declare @serviceObjective nvarchar(20)
-- 'basic' | 'S0' | 'S1' | 'S2' | 'S3'| 'P1' | 'P2' | 'P3' | 'P4'| 'P6' | 'P11' | 'P15'
-- declare @dbName sysname
declare @sql nvarchar(3000)
select @sql = replace(replace(replace(replace(
'Alter database [{{dbName}}] modify (Edition="{{edition}}", service_objective="{{service}}");
waitfor delay "00:00:05"
while (exists(select top 1 1 from (
select
*,
row_number() over (partition by resource_type, major_resource_id, minor_resource_id order by start_time desc) as rowNum
from sys.dm_operation_status) currentdb
where rowNum = 1
and resource_type_desc = "Database"
and major_resource_id = "{{dbName}}"
and state=1))
begin
waitfor delay "00:00:10";
end'
, '{{dbName}}', @DbName)
, '{{edition}}', case when @serviceObjective like 'S%' then 'standard'
when @serviceObjective like 'P%' then 'premium'
else 'basic'
end)
, '{{service}}', @serviceObjective)
, '"', '''')
select @sql as Script
I should give a shout-out to one of the Speaker Idol presenters at the PASS Summit last week whose topic was writing more readable dynamic SQL. I've used their technique above, using {{tokens}} in the string portion, then using REPLACE to replace the tokens with values. I've written my fair share of sprocs that generate and/or execute some dynamic sql and I always try to make it readable, and this technique is something I'll add to my toolbelt.
Here is a sample execution:
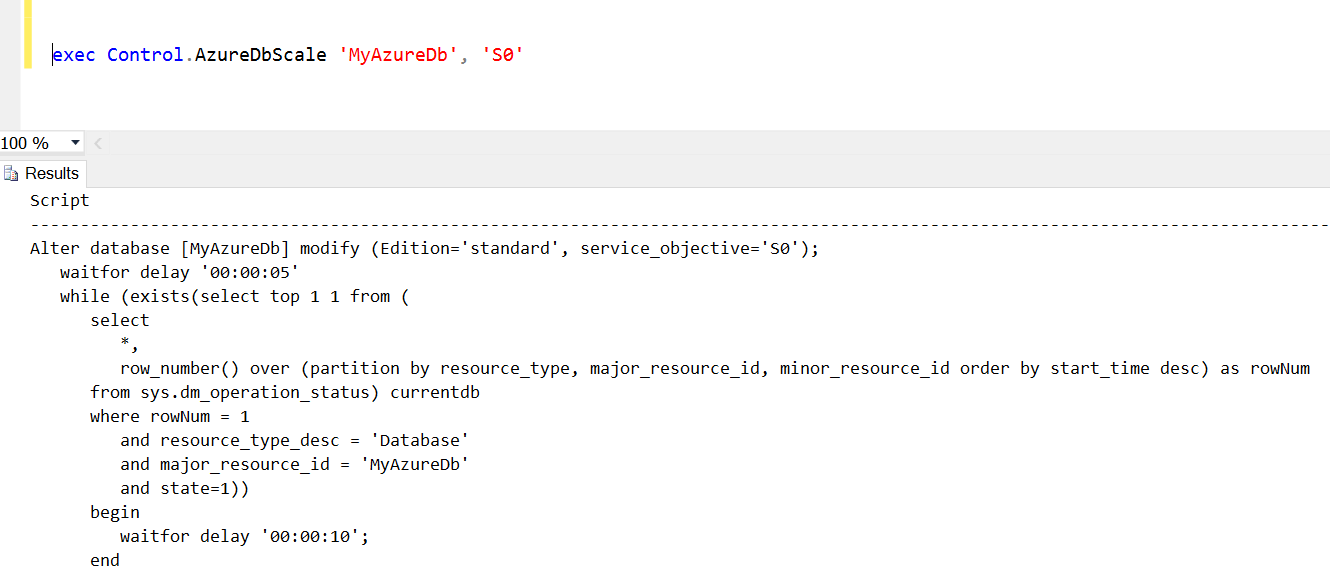
If you take the results and execute it while connected to an Azure SQL Server, in the master database context, it will change that database to service objective level S0 and wait until the change is complete.
This should help anyone who wants to scale an Azure SQL database and wait until the operation has completed.